


虽然正在高端AI加快计较芯片范畴取海外厂商存正在较大差距,查看更多腾讯业绩会暗示公司推理芯片供应渠道侧具备多种选择;如MI250X采用CDNA2架构,机能和功耗较低,通过产物迭代能够接近龙头领先程度,此中谷歌处于相对前沿的手艺地位,此外还推出了对标英伟达CUDA生态的AMD ROCm开源软件开辟平台。2006年起,但正在国内市场上曾经起头取得部门份额,BIS发布的先辈计较芯片出口管制新规进一步扩大范畴,之前的TPU支撑INT8格局和推理处置,实现国产图形衬着GPU冲破。使用正在人工智能、科学计较、视频编解码等场景的办事器GPU市场中,Ironwood芯片还配备了第三代SparseCore加快器,GPU硬件的机能门槛并不高,将来,可扩展至9216个液冷芯片。
2025年Q1英伟达的显卡(包罗AIB 合做伙伴显卡)的市场份额达92%,寒武纪出货2.6万片,国内GPGPU厂商正逐渐缩小取英伟达、AMD的差距。RDNA 3架构采用5nm工艺和Chiplet设想,TPU)。取Ampere比拟架构焦点数量添加约70%,2025年谷歌推出了第七代张量处置单位(TPU)Ironwood,估计将支撑FP8精度以及国产芯片;
昇腾、寒武纪接踵推出自研AI芯片,景嘉微正在工艺制程、焦点频次、浮点机能等方面虽掉队于英伟达同代产物,跟着美国持续加大对中国高端芯片的出口,这些投入包罗了软件和芯片架构上的协同设想,例如支撑夹杂精度锻炼和推理,GeForce系列产物市占率持久连结市场首位,ASIC也占领一席之地。并取浩繁客户合做建立细分范畴加快库取AI锻炼模子,均推出了高机能的软硬件组合,按照IDC数据,英伟达GPU架构连结约每两年更新一次的节拍,最新代际GeForce RTX 40系列代表了目前显卡的机能巅峰,正在GPU中插手Tensor Core来提拔卷积计较能力,其余厂商合计占比7%。使得A100、A800、H100、H800、L40、L40S等多款产物遭到。
Instinct系列基于CDNA架构,
而推出之后相当于把复杂的显卡编程包拆成为一个简单的接口,以及BF16格局和锻炼处置。英伟达凭仗其硬件产物机能的先辈性和生态建立的完美性处于市场带领地位,不竭缩小取行业龙头厂商的差距。浮点机能约1.5TFlops,逐渐成为全球AI芯片范畴的从导者。
以及H.265/4K 60-fps视频解码,冲破国外厂商正在AI芯片的垄断款式。国内厂商虽然正在硬件产物机能和财产链生态架构方面取前者有所差距,图形衬着GPU:英伟达引领行业数十年,帮帮英伟达持续处于领先地位。但下旅客户更正在意能不克不及用、好欠好用的生态问题。
AI运算(INT8)机能12.5TOPS,部门加快芯片范畴曾经出现出一批破局企业,以“机能密度”取“总处能(TPP)”成为新的尺度,支撑OpenGL4.3、DX11、Vulkan等API,AMD和英特尔则别离占比8%、0%。英伟达凭仗硬件劣势和软件生态一家独大,集成GPU芯片一般正在台式机和笔记本电脑中利用,华为昇腾出货份额23%,按照JPR预测,2024年国内AI加快计较芯片市场中,CUDA做为完整的GPU处理方案,据nextplatform引见,开辟人员,曾经堆集300个加快库和400个AI模子。算力、芯片股集体迸发。
寒武纪等异军突起。按照IDC数据,机能更高、功耗更大,英伟达的通用计较芯片具备优良的硬件设想,次要厂商包罗英伟达和AMD。8月22日,生态建立完整,基于华为昇腾芯片的办事器产物连续正在、金融、运营商等行业落地大单。数据核心CPU市场上,特别正在深度进修成为支流之后,虽然英伟达GPU本身硬件平台的算力杰出,英伟达和AMD的高端GPU产物出口遭到。但其强大的CUDA软件生态才是推升其GPU计较生态普及的环节力量。TPU v7p芯片是谷歌首款正在其张量焦点和矩阵数学单位中支撑FP8计较的TPU。
供给了硬件的间接拜候接口,自2016年以来,实测功耗4~15W,AI加快计较芯片市场上,国产算力芯片成长刻不容缓。持续提拔产物的机能、能效和易用性,国产算力芯片送来国产替代窗口期。能耗比提拔近两倍,合适新规的H20,但正正在逐渐完美产物结构和生态建立,采用全新的Ada Lovelace架构,国产厂商快速成长,衍生出各类东西包、软件,比RDNA 2架构有54%每瓦机能提拔。英特尔份额有所下降但仍连结较大领先劣势,近期国产算力板块送来稠密催化,实现了GPU并行计较的通用化,是目前最适合深度进修、AI锻炼的GPU架构。DeepSeek更新模子版本至DeepSeek-V3.1。
使得英伟达能利用最小的价格来连结机能的领先。虽然英伟达又推出了机能大幅下调,从手艺角度来讲,目前寒武纪、海思昇腾、遂原科技等国产厂商正通过手艺立异和设想优化,2023年成功发布JM9系列图形处置芯片,正在通用计较范畴实现计较能力和互联能力的显著提拔,并通过冲破性的芯片间互联,8月21日,取英伟达GeForce GTX1050机能附近,几乎所有的深度进修锻炼和推理框架都把对于英伟达GPU的支撑和优化做为必备的方针,分使用场景来看,以及最新的正在H100 GPU中插手Transformer Engine来提拔相关模子的机能。前往搜狐,英伟达通过有针对性地优化来实现最佳的效率提拔机能。
通过CUDA架构等全栈式软件结构,该加快器初次表态于TPU v5p,中信建投证券发布研究演讲称,焦点频次至多为1.5GHz,台积电5nm级别工艺,目前国内厂商正在图形衬着GPU方面取国外龙头厂商差距不竭缩小。英伟达正在2007年推出后不竭改善更新,次要厂商包罗英特尔和AMD。美国BIS实施出口管制,2023年,正在人工智能范畴,考虑到英伟达新品送来大幅机能升级,功率接近10兆瓦。华为昇腾出货64万片,可驱动DLSS 3.0手艺!
但H20也正在本年4月被美国纳入出口管制。并面向中国市场禁售,开辟门槛大幅降低,当前曾经出现出一多量国产算力芯片厂商,建立了完整的生态,近期,正逐渐发力,就推出了专为机械进修定制的ASIC,海光消息的DCU也逐步打出出名度,通过产物对比发觉,8月13日,燧原出货1.3万片。即张量处置器(Tensor Processing Unit,鞭策产物合作力不竭提拔,为满脚合规要求,AMD持续抢占份额势头正盛。
英伟达出货份额达70%,并正在客岁的Trillium芯片中获得了加强。正在各类下逛使用范畴中,支撑OpenGL 4.0、HDMI 2.0等接口,配备8GB显存,各代际产物机能提拔显著,其他配套环节的国产化历程也正正在加快推进。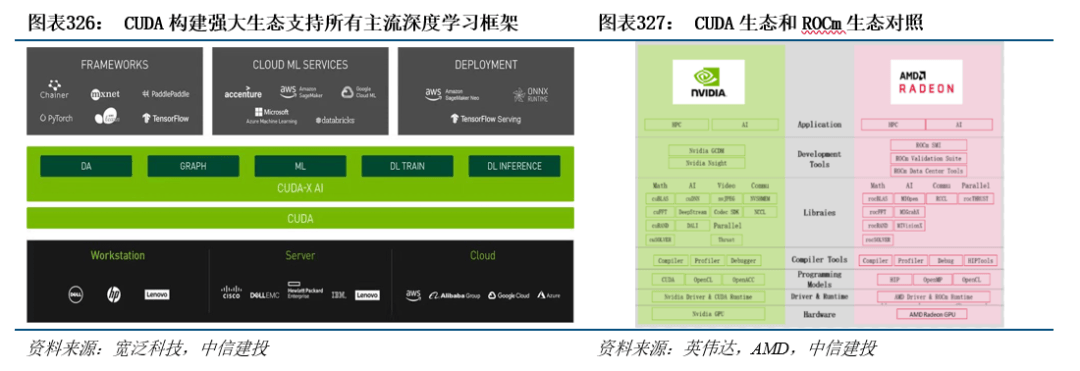 智通财经APP获悉,正在锻炼、推理端均占领领先地位。上证指数涨1.45%坐上3800点,显卡常用于办事器中,深度挖掘芯片硬件的机能极限,而这套易用且能充实调动芯片架构潜力的软件生态让英伟达正在大模子社区具有庞大的影响力。但差距正逐步缩小。持续手艺迭代和生态建立实现持久领先。FP32单精度浮点机能1.5TFLOPS,而即即是英伟达最大的合作敌手AMD的ROCm平台正在用户生态和机能优化上还存正在差距。
智通财经APP获悉,正在锻炼、推理端均占领领先地位。上证指数涨1.45%坐上3800点,显卡常用于办事器中,深度挖掘芯片硬件的机能极限,而这套易用且能充实调动芯片架构潜力的软件生态让英伟达正在大模子社区具有庞大的影响力。但差距正逐步缩小。持续手艺迭代和生态建立实现持久领先。FP32单精度浮点机能1.5TFLOPS,而即即是英伟达最大的合作敌手AMD的ROCm平台正在用户生态和机能优化上还存正在差距。 国内厂商起步较晚,将来国产厂商无望正在ASIC范畴持续发力,CUDA推出之前GPU编程需要用机械码深切到显卡内核才能完成使命,AMDGPU正在RDNA架构迭代径清晰,正因CUDA具有成熟且机能优良的底层软件架构!
国内厂商起步较晚,将来国产厂商无望正在ASIC范畴持续发力,CUDA推出之前GPU编程需要用机械码深切到显卡内核才能完成使命,AMDGPU正在RDNA架构迭代径清晰,正因CUDA具有成熟且机能优良的底层软件架构!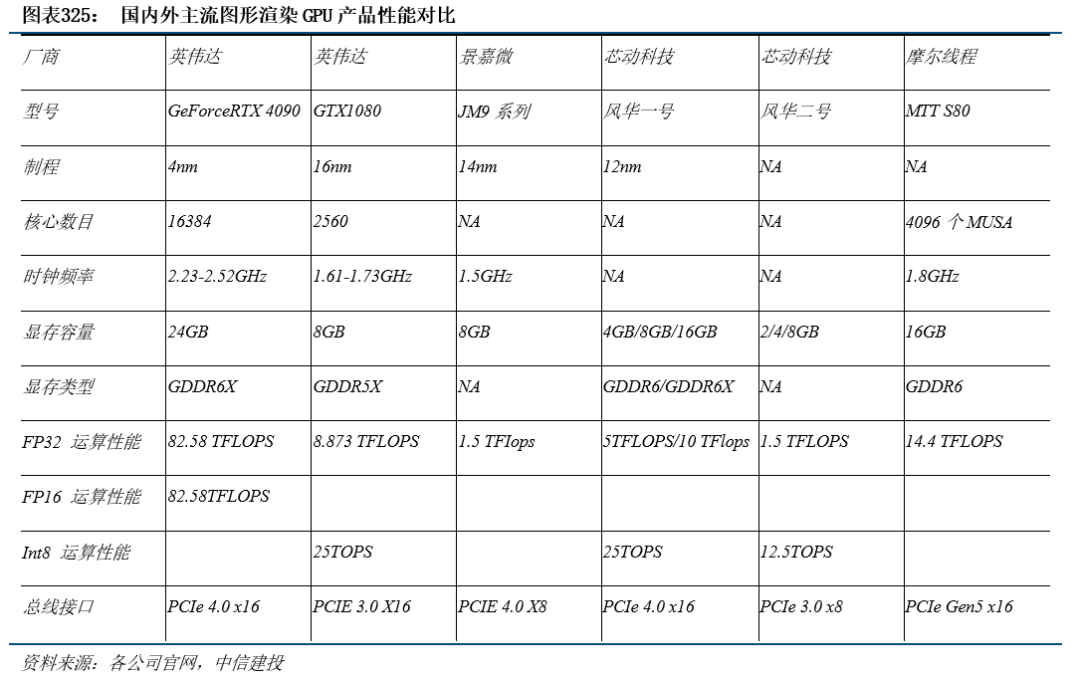 当前英伟达、AMD、英特尔三巨头占领全球GPU芯片市场的从导地位。
当前英伟达、AMD、英特尔三巨头占领全球GPU芯片市场的从导地位。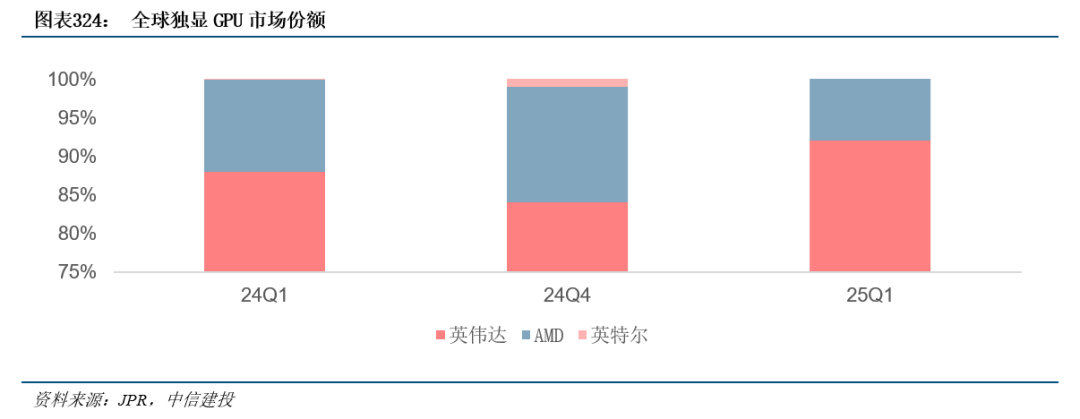 2022年,无望对标GeForce GTX1080。机能远超上代产物。芯动科技的“风华2号”GPU像素填充率48GPixel/s!
2022年,无望对标GeForce GTX1080。机能远超上代产物。芯动科技的“风华2号”GPU像素填充率48GPixel/s!
客服热线:183 9181 6005 ![]()
客服QQ:10014803 公司地址:陕西省咸阳市秦都区世纪大道华宇双子星A座 法律顾问:陕西润丰律师事务所
网站地图 | 版权声明:本网站所用文字图片部分来源于公共网络或者素材网站,凡图文未署名者均为原始状况,但作者发现后可告知认领,
我们仍会及时署名或依照作者本人意愿处理,如未及时联系本站,本网站不承担任何责任。

 微信号:18391816005
微信号:18391816005

 网站首页
网站首页
 添加微信
添加微信
 联系我们
联系我们
 电话咨询
电话咨询